Consideraciones de vSphere HA en VMware vSAN
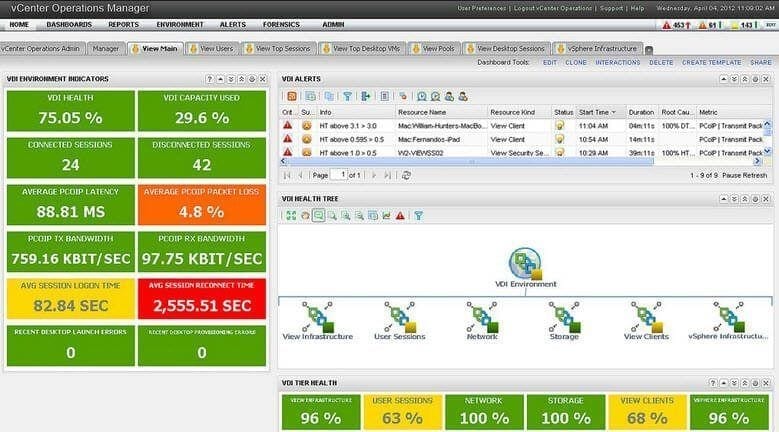
 VMware vSAN con vSphere HA proporcionan una alta disponibilidad para máquinas virtuales en un entorno vSphere. Si unos de los host falla y éste no está ejecutando ningún cálculo de maquinas virtuales, el impacto no se verá reflejado en ninguna máquina virtual, pero si el host que falla ejecuta máquinas virtuales, entonces vSphere HA reiniciará las máquinas virtuales en los host restantes del cluster.
VMware vSAN con vSphere HA proporcionan una alta disponibilidad para máquinas virtuales en un entorno vSphere. Si unos de los host falla y éste no está ejecutando ningún cálculo de maquinas virtuales, el impacto no se verá reflejado en ninguna máquina virtual, pero si el host que falla ejecuta máquinas virtuales, entonces vSphere HA reiniciará las máquinas virtuales en los host restantes del cluster.
vSphere HA ha sido rediseñado para trabajar con VMware vSAN comprendiendo los objetos que forman una máquina virtual, cuando se produce una partición de red, vSphere HA reinicia la máquina virtual en una partición del cluster que tiene acceso a un quorum de los componentes de la máquina virtual.
Antes de activar vSAN, asegúrate de que el cluster no tiene activado el servicio de HA, primero has de activar el servicio vSAN y seguidamente vSphere HA, la razón de esto es por que la red de heartbeat se realiza por la red de vSAN y no por la red de management network como si lo hace en una infraestructura sin VMware vSAN.
A diferencia que en un cluster de HA normal, VMware vSAN con HA no utiliza el datastore de vSAN para realizar heartbeat al datastore.
Hay que tener en cuenta que cuando se configura la política de máquina virtual NumberOfFailuresToTolerate, HA reserva recursos de CPU y memoria en los demás host del cluster para asegurar que en caso de fallo de un host, existan recursos suficientes para reiniciar una máquina virtual, pero VMware vSAN no interopera con vSphere HA para asegurarse que existe suficiente espacio libre en los demás host para todos los objetos y componentes de máquinas virtuales, si algún host falla y transcurrido 60 minutos por defecto, VMWare vSAN tratará de usar el espacio restante en los host para cumplir con los requisitos de políticas definida en la máquina virtual.
VMware recomienda HA y vSAN pero es muy recomendable tener en cuenta este tipo de situaciones para evitar llenar el datastore vSAN con los componentes y réplicas de máquinas virtuales tras un fallo en los host ESXi.
Gracias por leer nuestro blog, participar y compartir.